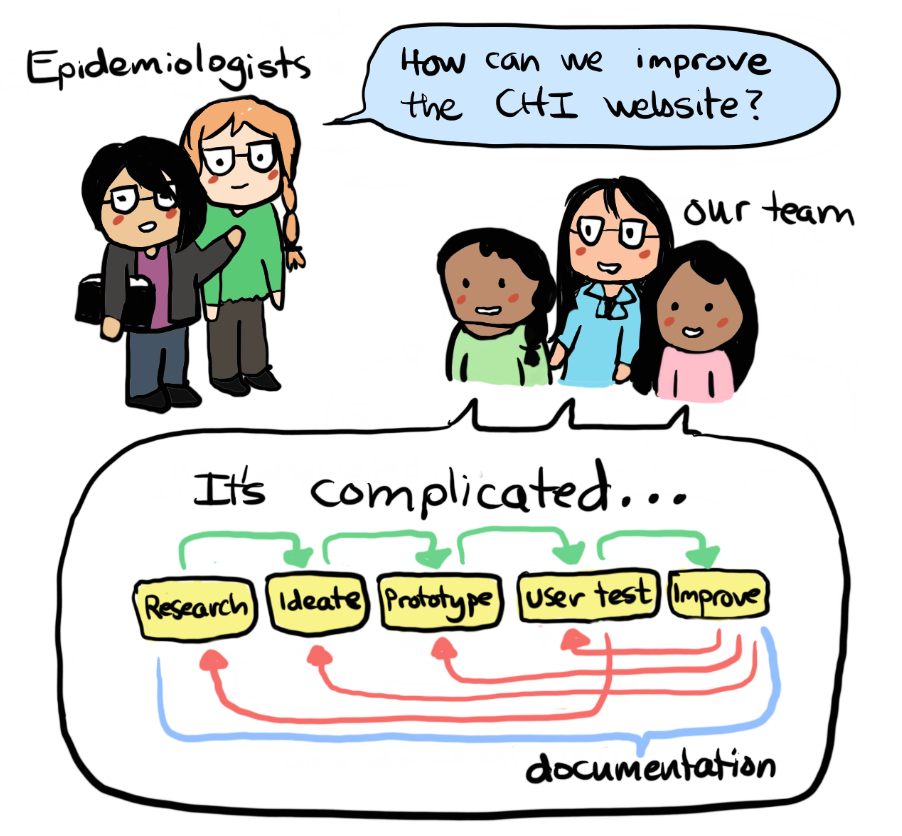
Information Problem

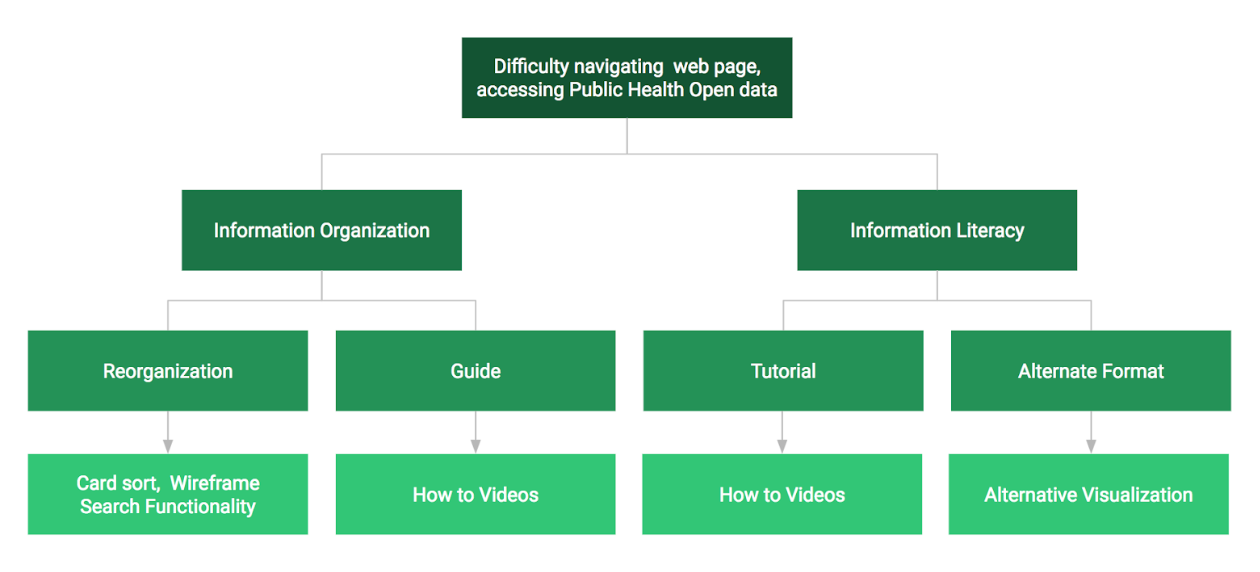
Our sponsors at the Department of Public Health manage a large amount of data and they are eager to share their information with their community health partners (researchers, non-profits and policy-makers), the media and the public. The Assessment, Policy Development & Evaluation Unit (APDE) has identified an issue with data accessibility and data literacy where users are unable to identify and access the datasets that they are looking for due to the rigid and industry specific organization. The user may become frustrated with the data being dispersed throughout different websites/locations and not organized intuitively. Sometimes the situation transforms into one where the user submits a data request to the Department and the Department will have to solve the data accessibility problem in a case by case manner. Repeated failures creates a sense of “learned helplessness” in the user which can be solved by better design (Norman, D, 2013). The user’s difficulties are signifiers of where the data portal can be improved.
The Department of Public Health wants to use the aggregated open data that is present on their data portal to get the public interested in what is happening in their neighborhood, issues concerning their demographic group to empower them and encourage the use of the data for community projects. This goes back to their organizational mission of providing the leadership and technical assistance to help community partners develop data-driven community programs.
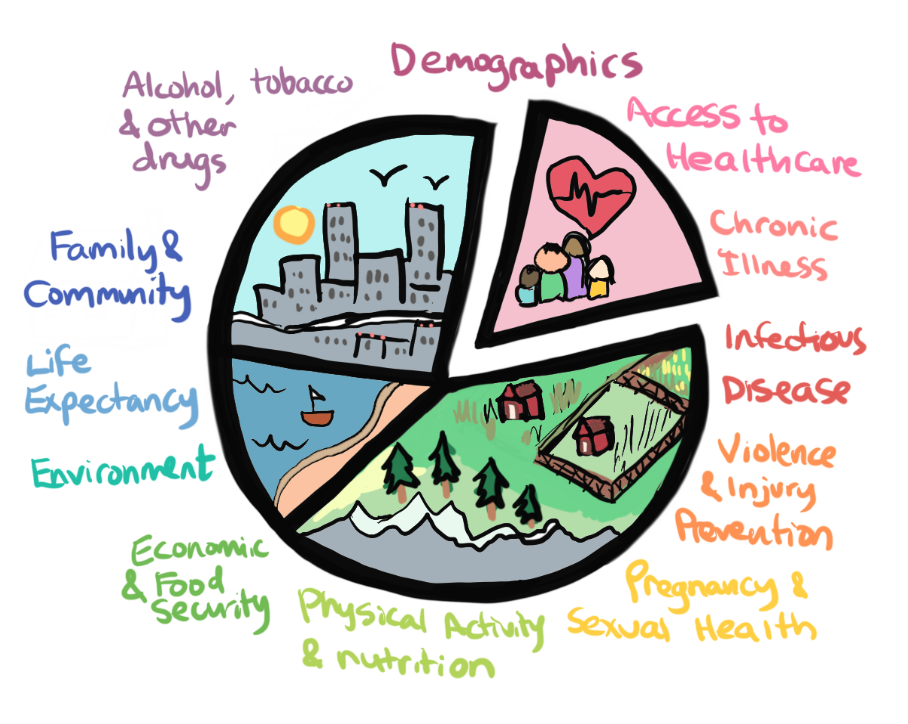
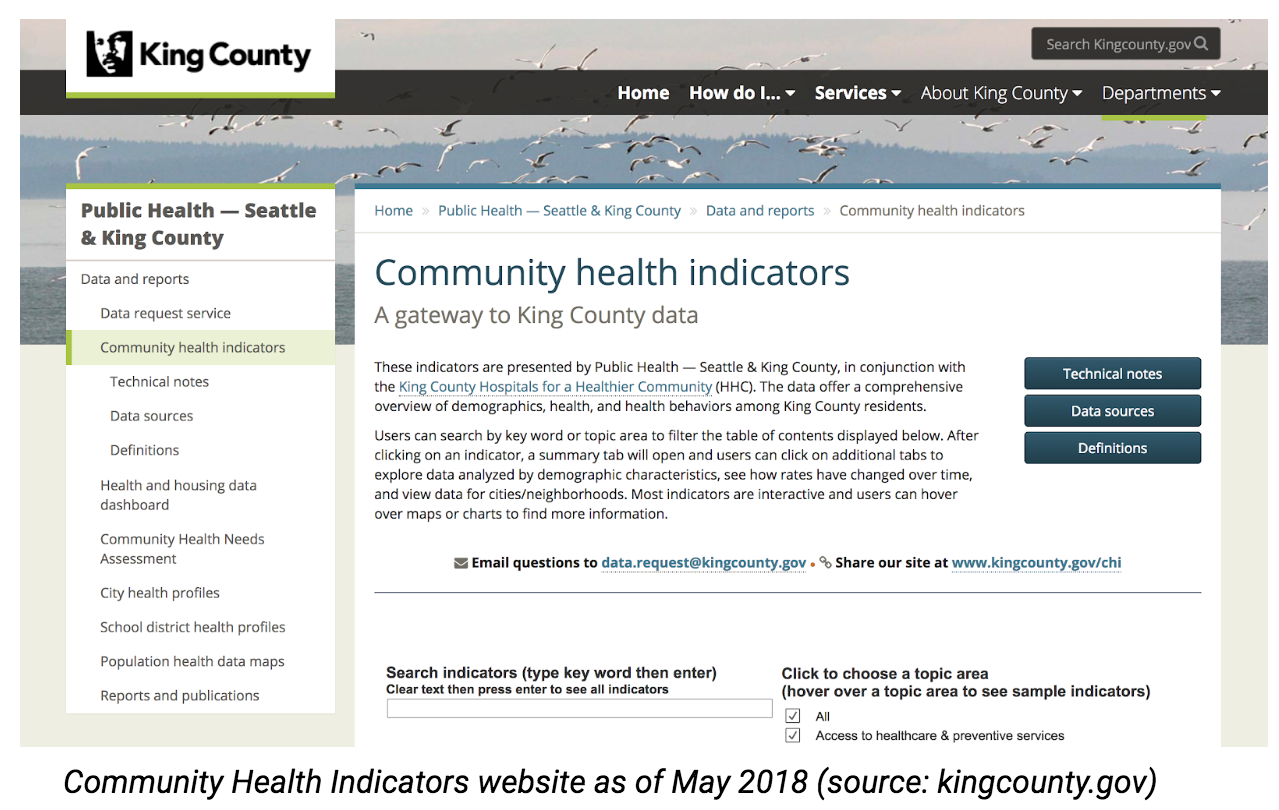
Our problem space involves the King County’s public health open data portal, the CHI website. These indicators offer information about the health of King county residents aggregated and archived over many years. The data is collected from the public through surveys and records from hospitals, schools and welfare programs. Epidemiologists in the Department of Public Health work to clean, aggregate the data, analyze,identify trends in the data and create visualizations from the data. The aggregated data and the visualizations are organized and stored in their servers and the King County IT department and Webmaster are responsible for organizing information and maintaining the content on the open data portal (CHI webpage).
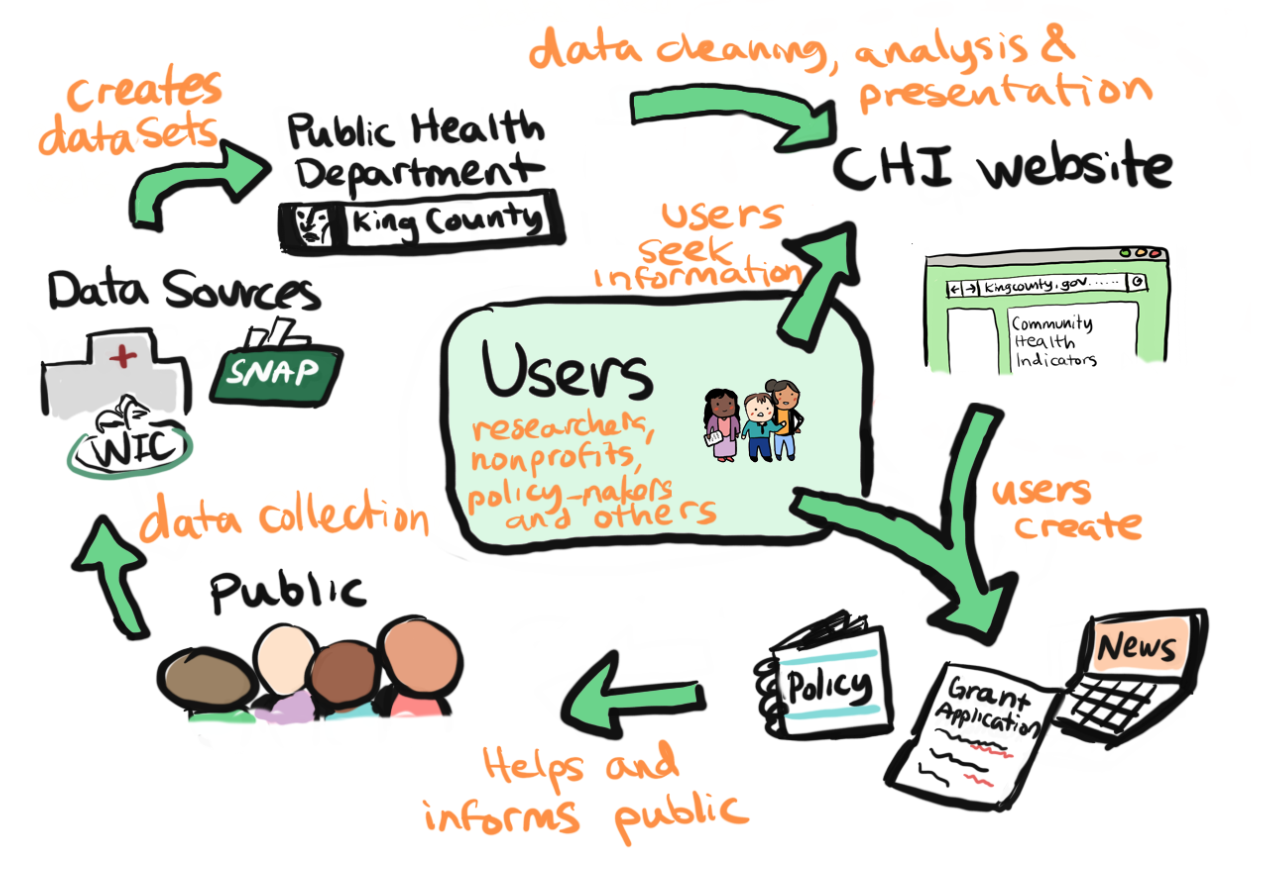
As the diagram indicates, the problem is centered around the users. Typical users who visit the CHI webpage seeking information are concerned citizens (public) and other users such as people from other government agencies, community organizations, health providers, non-profit organizations, media, advocacy groups, students, teachers, researchers and employers seeking information for creating employee wellness programs. These users seek information and data usually to create grant applications, informative articles/talks, course of action tasks and to create or evaluate existing policies. These would directly or indirectly benefit the general public.